
Just 67 lines of code to get notified instantaneously on each change for cheap flights, hot deals, new products, or any list of items.
Intro
In this tutorial, we are going build a script that visits a webpage every 5 minutes and sends a Facebook message if there is a new item. Nice, isn’t it ? In our example, the page we are scrapping displays super-cheap flights with a “price mistake” : Those deals disappear very quickly, that’s why we want to know it right away ! NB: The page is in French, but there is no need to read it.
If you are busy, just get the Github repo of the cheap flights scraper. For everybody else, let’s go together on this journey step by step :
mkdir my-scrapper
cd my-scrapperNice ! We just created a folder and cd into it.
Scrap
Let’s start with the main feature : scrap a website with NodeJs. We will use Puppeteer, let’s say that it’s a version of Google Chrome without the window to view it. As we don’t need to see the website but just to extract data from it, it fits perfectly for our scraper.
npm init // Creates a package.json file
npm i puppeteer --save // "i" stands for installPuppeteer is super easy to use. Let’s create a file called main.js and start working. I am using VS Code, but you can use any editor you want. That code below takes a screenshot of our page and stores it as example.png in the root folder.
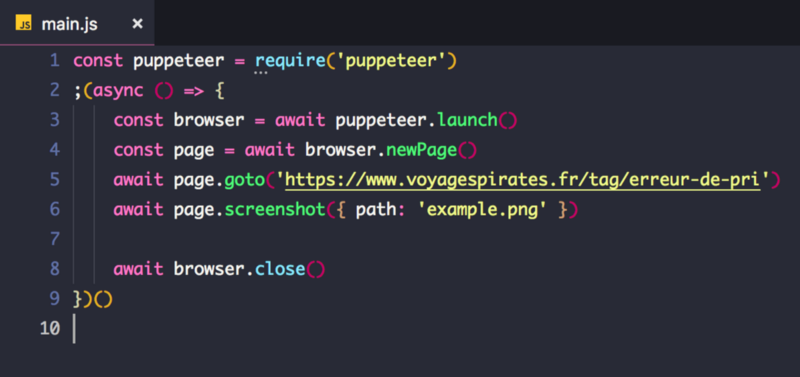
Let’s execute it :
node main.jsOk, this one was easy, but make sure that the image was generated. What we want to do now is to find a list of items in this page. We are using selectors to fetch this list. Let get only the item titles, there is no need to get images and texts.

The selector to get all the titles is h2 > a that means “all the <a> tags that have an <h2> tag as direct parent”. Let’s try to console.log it to check if you have the right content.
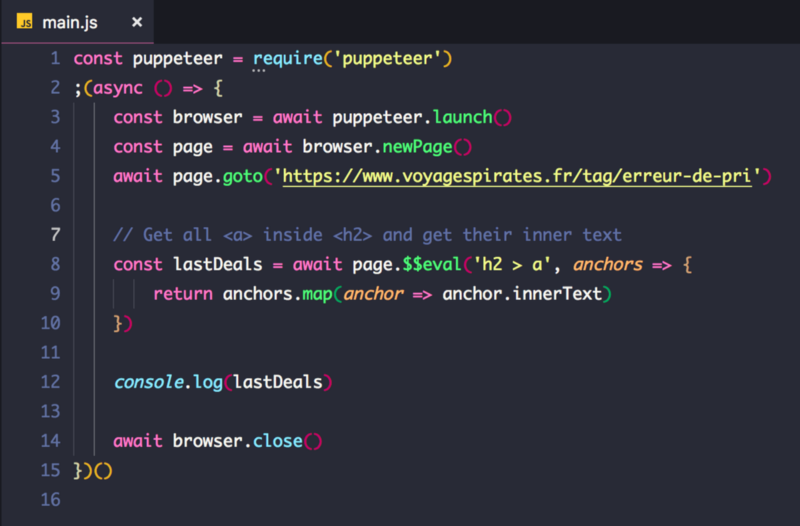
If you execute the file again (node main.js), you should receive an output in your terminal that lists all the items. Before going further, be sure that this output corresponds only to the items of the list, and that it’s the text you want. You may need to add a class selector like “a.item-title” to make it work
Compare and store
Once we have that data, we need to compare it with a previous extract. If the data changed, we send a message.
So how are we going to store the data : SQLite ? MongoDB ? MySQL ? No, This is not the fanciest NodeJs scraper, it’s the easiest NodeJs scraper ! Let’s be cheap and play for time, we are going to store it in a JSON file :)
One more thing, we don’t need to get all the items, but only the last one published, witch is actually the first one to appear in the page (on a feed-like system).

Let’s add “fs” to read and write files. Don’t forget to “require” it on top of the file.
npm i fs --save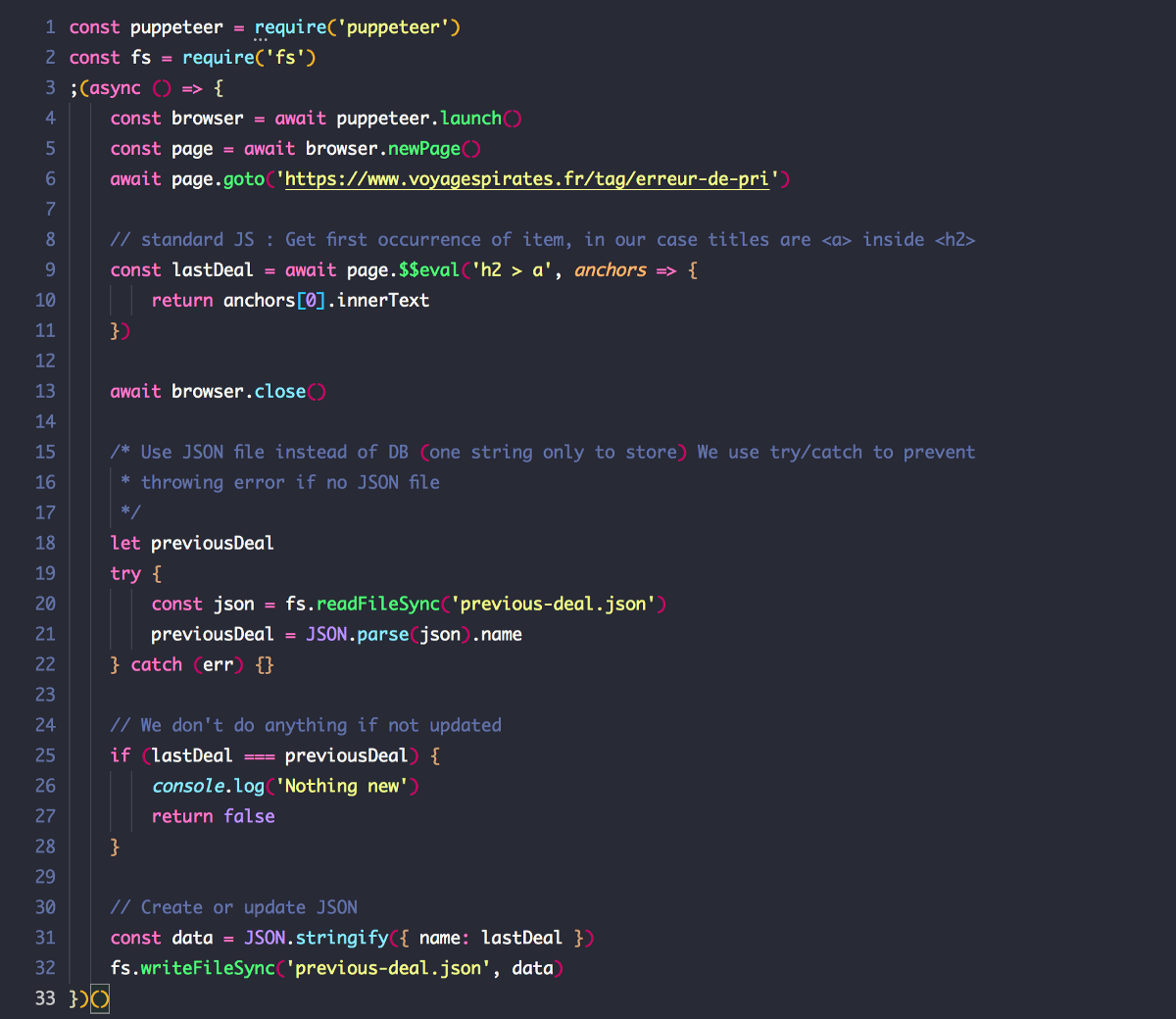
Ok, things are going a bit faster here. First we read a file called “previous-deal.json”. If the text in it is similar to the last deal from the website, we do nothing and stop the script.
If it’s empty or different, we update the JSON and we follow the script. Notice that we are using a try/catch structure because an error is thrown if the file does not exist, and we don’t want the program to stop.
You can try to execute the script again several times, eventually changing the content of the JSON file to trick the script and let it believe that the data changed.
Send Facebook Messenger notification
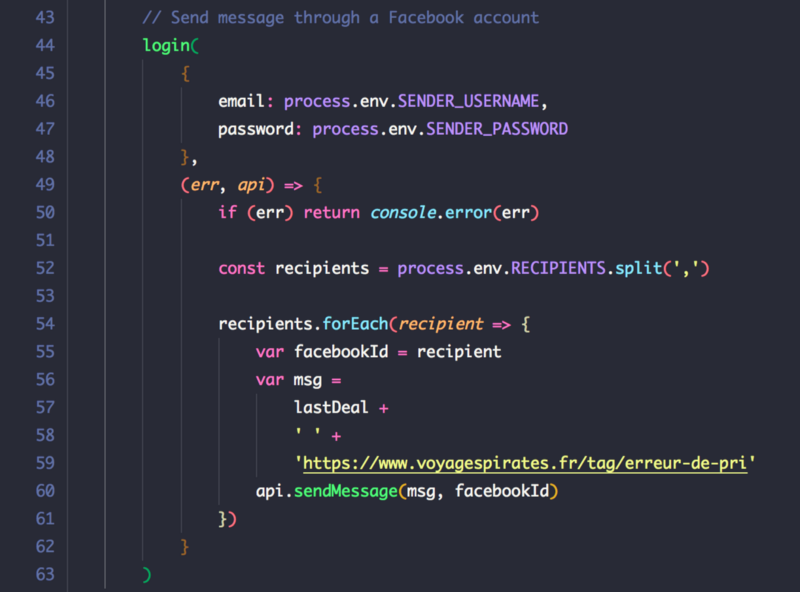
Now that we know if things changed, we need to send a notification to the recipients. We are using Facebook for that : it’s instantaneous, free, and easy to implement.
Once again, we will take a shortcut and we will NOT create a chatbot and manage tons of ids, authorizations and tokens. Instead, we will use an unofficial small library that allows to send messages as someone for whom you have the credentials. In order to keep our credentials and personal data safe, we will use dotenv too.
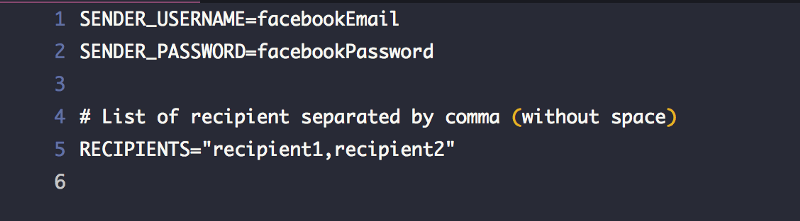
npm i facebook-chat-api dotenv --saveLet’s create a “.env” file with our sensitive data. This file remains private and will not be added to the version control system (git). You cannot send a message to yourself on Facebook so we need a sender account with login credentials (SENDER_USERNAME and SENDER_PASSWORD) and recipient accounts (Facebook IDs only)
Each Facebook account has an ID that you can find easily with this website. You will need to get the ID of each one of the recipients and add them in the double-quote string in the RECIPIENTS environment variable (see code below, replace the “recipientX” by the ID).
For the sender account, if you are a hacker you probably have that old account that you made some time ago. If not, just create a new one.
Repeat every 5 minutes
We will use a CRON job to run the script regularly :
npm i node-cron express --saveWe use node-cron to schedule tasks and expressjs to keep listening.
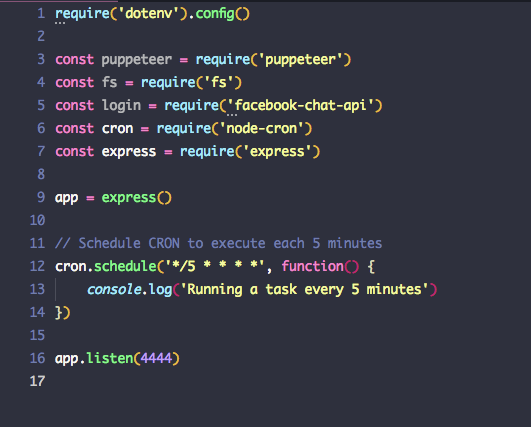
You just need to replace the console.log in line 13 by your code. Have a look at the final version here.
Deploy
Now that your Node js scraper is ready, you need to deploy it on a server that will always be available. I will not enter too much in detail as this part will be different based on your solution, whereas you use Heroku, Now, or another cloud service.
I use personally Digital Ocean servers with Ubuntu and had to install some libraries in order to run Puppeteer :(
That’s it ! Please let me know how it worked out for you. Let me know too if you know how we can make this scraper even simpler.
brunobuddy/cheap-flights-scrapper
Node scrapper to get instant Facebook messenger notification when new deal — brunobuddy/cheap-flights-scrappergithub.com

